
This is going to be interesting as I will be doing the data transfer between RDBMS(MySQL/Postgres) to Hbase. Nowadays there are many Options to do the Data Movement but my favorite is Nifi. I will not explain about setting up cluster or RDBMS in this blog. I Will write separate one to set up the cluster/nifi and RDMS.
Requirement
- Hadoop Cluster (HDP/CDH/CDP)
- Nifi
- RDBMS (Mysql or Postgres)
Steps
- Processor Selection
- Nifi and RDBMS Connection
- Nifi to Hbase Connection
Processor Selection
As we all know that nifi is full of processors and currently it has around 305+ processors, Which is much more than any other Opensource ETL tool. Lets take a look of full flow of nifi

Process Selection
So as per the task I have to select the processors. I need below task to perform using processors.
- List the tables from database [ListDatabase Tables]
- Iterate the tables [Generate TableFetch]
- Parse sql to create query [Extract Text]
- Execute query to fetch the data [ExecuteQuery]
- Convert fetch data into proper format [ConvertAvroToJson and SplitJson]
- Create the hbase table [ExecuteStreamCommand]
- Put the data into hbase [PutHbaseJson]
As you saw that i have used Eight processors in the flow and completed the data transfer along with data transformation. Let’s go one by one with these processors
Nifi and RDBS Connection
Nifi and RDBMS connection happened in first processor ListDatabase Tables, You need create a connection pooling services which need few connection parameters.

Add below properties in CONTROLLER SERVICES for mysql connection pool.
1
2
3
4
5
Database Connection URL: jdbc:mysql://localhost:3306/customer_data
Database Driver Class Name: com.mysql.jdbc.Driver
Database Driver Location(s): /<path>/mysql-connector-java.jar
Database User: root
Password: root
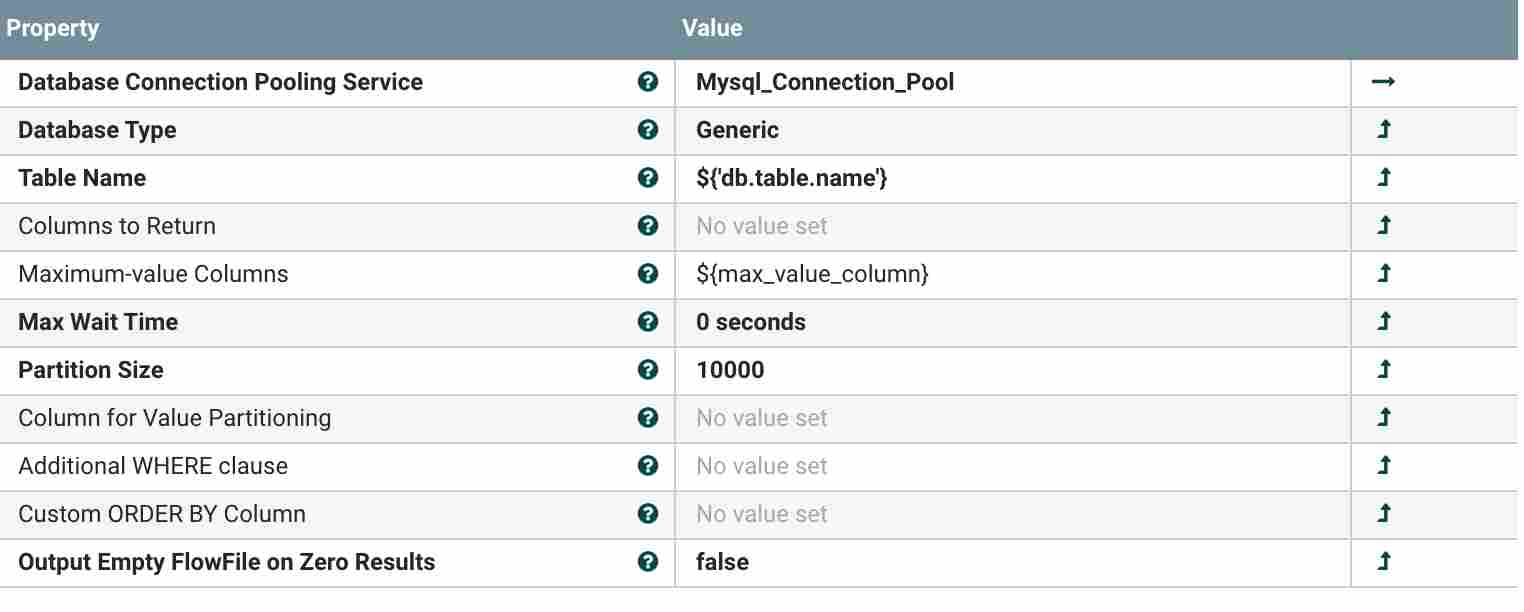
Another Processor is Generate TableFetch, This we help in fetching the details of table passed from ListDatabase Tables processor. You can see Table Name parameter which is coming from previous processor as well. Parameters which we need to set are below
- ${db.table.name} (table name coming from previous processor)
- ${max_value_column} (you can provide max column value like id or something)
Next Processor is Extract Text, It helps in extracting the text from Generate TableFetch flow files and convert them into attributes. You need to add a Property with below values
| Name | value |
|---|---|
| sql | ^(.*) |
Once you add the above properties, we need something to execute the sql and get the results, so we need executeSql Processor, You can see here that we have used same property which we have added as SQL select Query and same connection string which we have already used in list databases and generate fetchTable

After fetching the data from the tables, we need to convert in suitable format to push into hbase. As executeSql extract data in Avro format we need to convert it into json (which is best to put into Hbase), So lets convert it by setting below properties.
| property | value |
|---|---|
| JSON container options | array |
| Wrap Single Record | false |
Now as we have converted the avro into json files, we need to split it into each row to insert and we can do it by simply using below processor splitJson, set the property like below
| property | value |
|---|---|
| JsonPath Expression | $.* |
Nifi to Hbase connection
After we split data into rows, All we need to do is table where we can insert the data. We can do create table by using below processor, It requires script to create table which will check if the table is already there or not if not it will create one. We need to keep it at some place on anynode and pass the values in processor
1
2
3
4
5
6
#/bin/bash
if [[ $(echo -e "exists '$1'" | hbase shell | grep 'not exist') ]];
then
echo -e "create '$1','cf'" | hbase shell;
fi
| property | value |
|---|---|
| command Argument | hive@node1;/scripts/hbase.sh;${db.table.name} |
| Command Path | ssh |

Inserting data into hbase tables, using hbase connection pooling services, where we need to add the files path like below.
| property | value |
|---|---|
| Hadoop Configuration Files | /etc/hbase/conf/hbase-site.xml,/etc/hadoop/conf/core-site.xml |
In the process all you need to do is adding the Table Name, Row Identifier and column family. If you see above processor where i have created the hbase table we have column family as cf and Row Identifier should be unique for every row. So either you can give the primary key of the table or random id which is UUID to it.
| property | value |
|---|---|
| Table Name | ${db.table.name} |
| Row Identifier | id or {UUID()} |
| Column Family | cf |

I hope you get the idea of create a pipeline from RDBMS to Hbase, Please let me know if you face any issues and have any doubts. You can download the full template from here.
Happy Learning.